オープンキャンパスの手相占い作品を支える技術

2025年度オープンキャンパス作品「四国めたんのAI手相占い 〜照度差ステレオによる手のひらの立体形状推定〜」を制作した学士課程3年の鈴木温日です。この記事では作品に使用した技術に関して広く解説します。
プログラムのソースコードはGitHubで公開していますので、そちらも併せてご覧ください。
概要
照度差ステレオにより手の立体形状を推定し、その情報を元に手相占いをおこなう作品です。照度差ステレオは異なる方向から光を照射して得られた写真から立体形状を推定する技術です。
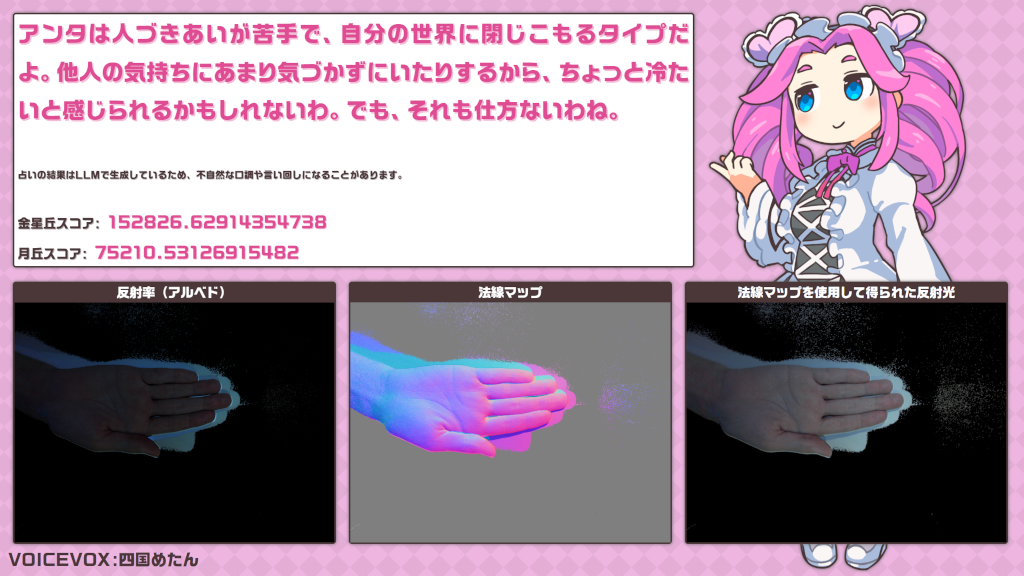
箱の中に手を入れてキー入力またはクリックすると、3方向から光を照射して写真を撮影します。すると、画面下に照度差ステレオにより得られた反射率と法線マップの画像およびそれらの画像からCGにより法線マップを使用して得られた反射光の画像と手相占いに使用する丘の大きさを数値化したスコアを表示します。立体的な形状が取得できていることが分かりやすくなるよう、照明の位置を変化させながら表示します。しばらくすると、ローカルLLMによってスコアを基に作成したプロンプトから生成された占いの結果を表示し、TTSによる読み上げをおこないます。読み上げが終わると画面のスクリーンショットのURLが格納された二次元コードを表示します。
ハードウェア
- NVIDIA GeForce RTX 2080 Ti搭載のPC
- Arduino Uno R3
- BSW50KM02BK(カメラ)
- OSW4XME1C1S-100(LED)
など
ここで挙げたものはすべて研究室にあったものです。使用した私物は一部のダンボールと後述する光源の位置の推定に使用した球のみとなります。
作品の右側の天井の照明の影響を減らすために使用した全面を黒く印刷した紙は、大学のプリンタで印刷しました。
構成

GitHubリポジトリのLanguagesの欄からも想像がつくかと思いますが、プログラムは大きく分けるとPythonで記述した部分とTypeScriptで記述した部分に分かれています。Pythonで記述した部分はメインのプログラムであり、LEDとカメラに関する処理や画像処理に関する処理をおこなっています。一方で、TypeScriptで記述した部分はJavaScriptにトランスパイルし、ブラウザ上で動作してキーボードやマウスの入力を受け取ったり映像や音声を出力するUIとなる部分になります。
main.pyを実行すると、最初にsubprocessによりVOICEVOX ENGINEが起動されます。VOICEVOX ENGINEはTTSソフトであるVOICEVOXを構成する部品の一つであり、読み上げさせたい文字列をHTTPリクエストとして渡すと音声合成をおこなってレスポンスとして音声合成の結果が得られるソフトウェアです。無料で使用でき、プログラムからも呼び出しやすいため使用しました。Python側のプログラムから起動されますが、起動された後はブラウザ側とのみ通信します。レスポンスとしては波形データだけでなく、各音の発声の長さなどの情報が取得できるため、このプログラムではリップシンクに利用しています。
次に、スレッドを分けてHTTPサーバーを起動します。このサーバーはあらかじめ用意したHTMLやTypeScriptをトランスパイルして得られたJavaScriptのファイルなど、UIの表示に必要なデータを提供します。また、特定のディレクトリ下へのアクセスをイベントとして処理し、queueを使ってメインループ側でこれを待機させるようにしています。これは入力待ちなどに利用しています。
それから、SeleniumでGoogle Chromeを起動します。Seleniumを使用した理由としては、画像のダウンロード機能のためにスクリーンショットを撮影する必要があったというのが最も大きいですが、Python側のプログラムとの通信の処理が楽というのもあります。当初はWebSocketによって通信をおこなうことを考えていましたが、HTTPサーバーと別にWebSocketサーバーを立てる必要がある、非同期処理で書く必要があるなどで手間がかかりプログラムも複雑化しやすかったため、利点としてはむしろ後者の方が大きかったと思います。Seleniumのexecute_scriptでCustomEventを発火させ、detailに情報を載せることでブラウザ側にデータを送信しています。画像についてはOpenCVのimencodeで可逆圧縮のWebPに変換し、それをbase64でエンコードしてから送信し、ブラウザ側ではdata URLで扱っています。また、Google Chromeを使用したのは、CSSのtext-spacing-trimプロパティ(約物の幅を自動で調整するプロパティ)にGoogle Chromeが対応しているのに対してFirefoxは対応しておらず、Google Chromeを使用するほうが少しでも望ましいテキストの表示が得られると判断したためです。
LEDの制御にはArduinoを使用しており、ArduinoとPython側のプログラムの通信にはシリアル通信を使用しています。また、使用したカメラはウェブカメラのため、OpenCVのVideoCaptureで映像を取得しています。
占い結果の生成にはOllamaを使用しています。OllamaはローカルでLLMを動作させることができるツールで、VOICEVOX ENGINEと同様にHTTPでアクセスすることでLLMを使用できます。ただし、ここでは公式で用意されているOllama JavaScript Libraryを使用しています。ローカルLLMを使用したのは、無料で使用できること、外部に情報が漏れる心配がないこと、といった利点があるからです。
画像をサーバーにアップロードし、画像のURLを格納した二次元コードを表示する機能について、同様の機能を実装している過去のオープンキャンパス作品では栗原研のウェブサーバーにアップロードしていたようですが、この作品では大学のウェブサーバーにFTPで接続してアップロードしています。特に申請などなしで個人が静的なウェブサイトを公開できるサーバーが大学には存在するため、動的コンテンツを提供する必要のない今回はそちらを使うほうが手軽だと判断しました。
プログラムの詳細

照度差ステレオでは光源の方向が既知である必要があるため、作品を動作させる前にlight.pyで光源の方向を取得する必要があります。光源の方向の取得は球に光を反射させ、それを撮影することでおこなっています。私物のERGO M575Sというトラックボールの青い球を使用しました。私物であり気軽に使えるのと、よく光を反射するため画像処理がしやすかったので使用しました。球が転がらないよう、スティックのりのキャップに球を乗せて撮影することが多かったです。画像から球を検出する手法として、最初はハフ変換を使用しようと思いましたがうまくいかなかったため、HSVに変換してから閾値処理で球の色の部分の領域のみを取り出してその外接円を球の位置とみなすことにしました。色に依存するため照明の条件などが整っている必要はありますが、条件を揃えると非常にうまく安定して検出できました。光を当てない場合との差分画像を使用することで、上に示した写真のように他の光源が反射していても正しく光源の方向が取得できます。
main.pyでは、最初に
for _ in range(99):
cap.read()のように書いてある部分がありますが、これはカメラの起動直後(最初にcap.read()を実行した直後)だと写真の明るさが安定しないため、しばらく撮影させる処理です。その後に1枚写真を撮影します。背景差分で手の領域を切り抜くため、何もない状態を撮っています。
キーが押されたら撮影します。ここでは3方向から光を当てた写真のほか、光を当ててないときの写真も撮影しています。これは最初に撮影した何も写っていない画像との差を計算して背景差分に使用するほか、光を当てた写真との差を計算して装置以外の光の影響を除去するのに使用します。なお、差を計算する前にカメラ応答関数の逆関数を画像に適用して、入射光強度の画像に変換しています。カメラ応答関数は不明なため、露光時間を変更して撮影した写真をもとに算出することも検討しましたが、明らかに不自然な関数が得られたので使用せず、\(\gamma=2.2\)に対するガンマ補正と仮定することにしました。カメラ応答関数の逆関数の適用は少しでも高速におこなうため、LUTを使用しています。
ここからは反射率と法線マップを作成する処理になります。ランバート拡散反射モデルでは、反射率(プログラムではimg_albedo)を\(\rho\)、光源の向きのベクトルを\(\boldsymbol{s}\in\mathbb{R}^3\)、法線ベクトル(プログラムではimg_normal)を\(\boldsymbol{n}\in\mathbb{R}^3\)とすると、観測される明るさ\(i\)は以下の式で表せます。このモデルは平行光源を想定していますが、実世界では平行光源を実現できないため、この時点で誤差が生じます。
\(i=\rho\boldsymbol{s}^\mathrm{T}\boldsymbol{n}\)
この式を各光源ごとに立てることで連立方程式が得られます。光源の向きの行列(プログラムではlight)を\(\boldsymbol{S}=\begin{bmatrix}\boldsymbol{s}_1&\boldsymbol{s}_2&\boldsymbol{s}_3\end{bmatrix}\in\mathbb{R}^{3\times 3}\)、観測される明るさ(プログラムではimgs)を\(\boldsymbol{i}=\begin{bmatrix}i_1&i_2&i_3\end{bmatrix}^\mathrm{T}\in\mathbb{R}^3\)として
\(\boldsymbol{i}=\rho\boldsymbol{S}^\mathrm{T}\boldsymbol{n}\)
と表せます。これを変形して
\(\rho\boldsymbol{n}=(\boldsymbol{S}^\mathrm{T})^{-1}\boldsymbol{i}\)
とすることができ、\(\rho\boldsymbol{n}\)(プログラムではg)を求めることができます。ここで、法線ベクトル\(\boldsymbol{n}\)は単位ベクトルなので、反射率\(\rho\)は
\(\rho=\|\rho\boldsymbol{n}\|_2\)
で求めることができ、法線ベクトル\(\boldsymbol{n}\)は
\(\boldsymbol{n}=\dfrac{\rho\boldsymbol{n}}{\|\rho\boldsymbol{n}\|_2}\)
で求めることができます。今回の作品では入力画像がRGBカラー画像であり、\(\rho\)は3チャンネルあるため、法線ベクトルを求める演算は\(\rho\boldsymbol{n}\)をグレイスケール化してからおこなっています。
以上を各画素についておこないます。ただし、光源の強度は同じである必要があります。プログラムでは写真の明るさがなかなか安定せず、明らかにばらつきがあったため、各画像の明るさが同じになるよう事前に自動で調整するようにしています。また、Pythonはインタプリタ型言語のため、for文を回して各画素について処理をおこなうと時間がかかってしまいます。そこで、全画素についての行列を作成し、NumPyの行列演算機能で上記の演算を一括でおこなっています。
求めた法線マップからY方向の傾きを取得し、背景差分で求めた手のマスク画像の重心から算出した金星丘や月丘がありそうな部分の傾きを集計して、2つの丘のスコアを算出します。その後、反射率と法線マップ、スコアをブラウザ側に送り、処理を委ねます。このとき、解説などに使用することを想定し、スコアの算出方法が分かる画像を作成してファイルとして出力するようにしています。
撮影後に表示される法線マップを使用して得られた反射光の画像は、Three.jsを使用して描画しています。照度差ステレオにより得られた反射率と法線マップの画像を適用したマテリアルを作成し、それを平面のメッシュに適用し、メッシュと同じ大きさの平行投影のカメラでそれを写すことで、画面全体にぴったり面が映るようにしています。光源としては環境光と点光源を用意し、点光源をメッシュに垂直な軸を中心に回転させることで、立体的に見せています。
画像処理により得られた2つのスコアについて3段階の評価をおこない、6通りのプロンプトを生成し、そのプロンプトをLLMに読み込ませて占いの結果を生成しています。同じプロンプトに対して似通っているものの毎回異なる結果が得られます。Thinkingモデルなのでデフォルトで思考過程が出力されますが、結果の出力に時間がかかってしまうためプロンプトの先頭に/nothinkと書くことで抑制しています。口調をプロンプトで指定しており、少しでも口調を寄せるためにプロンプトも寄せたい口調に合わせています。しかしながら、語尾を指定すると取ってつけたように語尾を追加することが多々あるので、出力を正規表現によって置換することで、ある程度抑制しています。二人称は片仮名で「アンタ」としていますが、平仮名の「あんた」が出力されることがあったのでこちらも置換しました。来場者は手相について知識のない人がほとんどであると判断したため、手相の用語は使用しないよう指示しました。否定形のプロンプトであったため効きが悪いのか、本番まではこの指示を無視することがかなり多かったのですが、本番はうまく動いており、無視されることはありませんでした。ただし、不自然に手相の丘の名称である「金星」や「月」といった言葉が文中に含まれるようになっている気はしました。
LLMはQwen3-30B-A3Bを使用しました。このモデルはパラメーター数は300億と大きめですが、そのうち活性化するのは30億パラメーターのみであるため、作品を動作させているVRAM容量が11GBのPCでも問題なく動作し、このPCで動かせるLLMでは最も高い性能を発揮できると判断しました。オープンキャンパスの直前の7月28日にアップデート版のQwen3-30B-A3B-Instruct-2507が公開されましたが、直前であったため取り込んでテストする余裕がなく、今回は古いモデルを使用しました。
LLMによる占いと音声合成の読み込み時に何もないのは少し寂しかったため、待ってほしいという旨を喋らせることにしました。この台詞は常に同じため、VOICEVOX ENGINEの出力データ(各音の長さなどのデータと波形)を保存しておいてそれを読み込むようにしています。手のひらの認識に失敗した場合にも同様に喋るようになっています。本番では認識に失敗することは一度もなかったため、この台詞は使用されませんでしたが。
見た目
オープンキャンパスで動作させる作品として、多くの人に関心を持ってもらえるよう、見た目にも力を入れました。Morisawa Fontsが学割により年額990円と非常に安く利用できるので契約し、それを積極的に使用しました。
最初はpygameを使いUIも含めすべてPython上で動作させることを想定していましたが、表示に関する機能が全体的にCSSのほうが優れていると判断し、ウェブ上でUIを構築しました。CSSでは両端揃え(text-align: justify)のような見た目を整える機能やドロップシャドウ(filter: drop-shadow())やアニメーションといった見た目を派手にする機能が揃っていてかつ簡単に扱えるため、すぐにいい感じの画面を作成することができました。最初は画面下部の写真をもっと小さくしていたのですが、照度差ステレオについて関心を持ってもらいたかったため、キャラクターに画像を被せることを許容することで画像を大きくしました。
キャラクターの画像には四国めたん立ち絵素材を使用し、GIMPでパーツごとに分けたPNG画像にして使用しました。キャラクターとして四国めたんを使用したのは、VOICEVOXに初版の段階から収録されていて、収録されたキャラクターの中では比較的知名度が高かったのと、大学が四国にありご当地キャラクターとしての側面もあったためです。

ロゴと説明用のプリントはInkscapeを用いて作成しました。ただし、ロゴの背景の魔法陣と文字はLuaLaTeXでTikZを使用して作成してから、それをInkscapeで加工しています。背景の魔法陣に関しては正確な作図がグラフィカルなツールで描くよりも容易である、文字に関してはInkscapeではツメ組を自動でおこなうことができないから、という理由でこのような方法を採用しています。ロゴ以外の文字については長文も多いため、ツメ組ではかえって読みづらくなると思い、Inkscapeでベタ組にしました。魔法陣について、TikZは平方根や三角関数、ループ処理、パスに沿ったテキストの配置など、高度な作図機能を有しているため、ほとんどはTikZの機能のみで作図していますが、それでも融通が効かなかった部分はLuaで関数を作成してカバーしています。ちなみにこの記事に掲載した構成図もTikZで作成しており、ロゴの背景の魔法陣やツメ組した文字とともにGitHubでソースコードを公開しています。

